Abstract
Particle-based fluid simulation is one of the most prominent forms of computational hydrodynamics. The fluid volume is discretized into a finite number of particles. Extracting a surface from this set of particles is a crucial part of visualizing the computed fluid data. Reconstructing distinct features as well as uniform areas while concealing the spherical nature of the data has proven to be complicated. In this thesis, we discuss techniques researchers have developed that try to accomplish this. Our sources propose algorithms that smooth the way to high-quality fluid visualization in real-time, allowing the usage in interactive applications like video games or simulations.
Acknowledgements
First and foremost, I want to thank Prof. Dr. Elmar Schömer and Dr. Rainer Erbes for being my supervisors during the writing of this thesis. They are always able to move their students in the right direction and are ready to help where help is needed.
I also want to thank Yan Chernikov, the creator of the YouTube channel TheCherno where he uploads excellent videos on topics related to computer graphics and programming in general.
Related work
Particle-based approaches to fluid dynamics have made an extensive evolution during the last decades. Researchers had moved from rendering particles as spheres to fluid mesh extraction using for example an algorithm called marching cubes (Müller et al., Williams, Yu and Turk). But with GPUs becoming more and more powerful, screen-space techniques for rendering particle-based fluids - like the one discussed in this thesis - have emerged and gained popularity (Wu et al., van der Laan). The core difference to traditional methods is that the surface extraction happens for every pixel of the screen. Thus, only the visible parts of the fluid are actually computed and the rendered image is of high quality due to the fine details that can be extracted at the pixel-level.
There are countless papers introducing new techniques for rendering different parts of a fluid. Ihmsen et al. for example propose a method for rendering foam and bubbles at wave crests.
Particle-based fluid simulation has even made its way into deep learning with Ummenhofer et al. among others developing a neural network that can predict new particle positions from the previous simulation step.
Introduction
The primary source of this thesis is the paper A Real-Time Adaptive Ray Marching Method for Particle-Based Fluid Surface Reconstruction, written by Tong Wu, Zhiqiang Zhou, Anlan Wang, Yuning Gong and Yanci Zhang. In addition to reformulating its contents, we introduce details about our implementation to further build an understanding of the authors' work and to supply anchor points for anyone attempting to develop an implementation for their own.
Williams states that computational fluid dynamics consists of three phases: simulation, extraction of a renderable representation, and rendering itself. This work focuses on the latter two. The authors of our primary source build on top of existing advancements in the field and propose algorithms and data structures that aim to make those methods capable of running in real-time.
Whenever we write "the authors" or "Wu et al." we are referring to ideas coming from our primary source. We distinguish between our and others' thoughts by mentioning their origin. Unfortunately, we did not have the time to implement every aspect of the authors' algorithm. Details on the parts we implemented can be found in the Implementation subsections of each chapter.
Structure
We will start by establishing some notation and explain the reasoning behind our choices regarding implementation details like programming language and libraries. Then we will introduce the theoretical backbone behind particle fluid simulation in Smoothed Particle Hydrodynamics. Since there are many parts to the described algorithm that have to be addressed, we will give a broad overview in the section Pipeline overview before going into more depth explaining all steps necessary for displaying a fluid on screen. Finally, we will present our results by showing screenshots of our application together with some measurements that qualify the different techniques applied.
Technology
We decided to use C++ together with Vulkan as our graphics API. Vulkan is a state-of-the-art graphics API allowing for very low-level access to GPU processes and resources. Although this is not strictly necessary for the application discussed here, learning about Vulkan is as interesting as it is useful for moving deeper into graphics programming, which is why we chose to use it. Vulkan opens the door to vast improvements in computation time by letting the user decide which computations should run in parallel, what memory is accessible where, and much more. By leveraging more of Vulkan's features, the computation time needed by our implementation could reduce by orders of magnitude. These possibilities are discussed further in the chapter Future work.
Other libraries that were used are listed here, some of which are described in more detail later:
- Dear ImGui for the graphical user interface
- GLFW for window management
- Partio for importing particle data
- Eigen and glm for math
- CompactNSearch for neighborhood search
- SPlisHSPlasH for dataset generation
The code for our implementation can be found on GitHub.
Terminology
This is a collection of mathematical notation and symbols we use throughout this thesis.
Notation:
- Vectors and matrices are written in bold font. The names of vectors are in lower case and those of matrices are in upper case:
- is the -norm of the vector .
- is the unit vector pointing in the same direction as .
- is a four-dimensional homogenous vector corresponding to a three-dimensional position vector . In computer graphics, homogenous coordinates are used to calculate the projection of three-dimensional objects to the two-dimensional screen.
- is the -th entry of the vector . This is to distinguish between element indices and other types of indices the vector inside the brackets could have.
- is the entry in the -th row and the -th column of the matrix .
- is the adjugate of the matrix
Symbols:
- : the particles' radius
- : neighborhood radius
- : characteristic neighborhood matrix of the particle
- : the density threshold at which the fluid's surface is assumed
Fundamentals
This chapter aims to equip the reader with the mathematical and conceptual basics of particle-based fluid dynamics. We will introduce the underlying theory of Lagrangian fluid simulation and its physical relevance. Afterward, we explain how our representation of the fluid is generated and how it is stored in memory.
Smoothed Particle Hydrodynamics
The macroscopic real world we are seeing and experiencing every day is of continuous nature. Computers on the other hand are unable to capture this continuity reasonably. Thus, computer scientists have to invent ways of discretizing physical problems to be able to construct simulations for them. Smoothed Particle Hydrodynamics (SPH) is one such method of discretization. Originally invented for the simulation of gravitational systems in astronomy, it is now widely used in fluid simulation.
There are two prominent mathematical theories describing the computational simulation of hydrodynamics (Monaghan):
In Eulerian hydrodynamics, the fluid's properties are observed at fixed locations in space, usually arranged in a grid. This technique has built the foundation of computational fluid dynamics as we know it today.
In Lagrangian hydrodynamics, the fluid's properties are carried through space by individual particles. These quantities are evaluated at the particles' freely moving positions instead of at fixed grid points.
Both methods are still in simultaneous use today as they differ in computational efficiency and physical accuracy. The choice of a best fit depends heavily on the application.
SPH belongs to the Lagrangian category. The core idea is to approximate a continuous function with a finite set of particles . Each particle consists of a position and an associated feature . Together, these form the set of particles with . Here, is a generic set of feature values that is dependent on the context of the problem. In the application discussed in this work, the feature of interest is the fluid's density. This can be represented by a scalar in , which is why we set . In other applications for example, it is common to see and to be interpreted as the particle's velocity (see Ummenhofer et al.).
The continuous distribution of a feature in three-dimensional space is given by a function
Iterating over all particles , can be approximated by the finite sum
where is called the smoothing kernel, is the particle's density and is the particle's mass. In our case, the feature we are seeking to compute is the fluid's density , so we set and therefore - assuming all particles have identical mass - the equation simplifies to
Physically speaking, has the unit meaning the kernel function has to have the unit .
Surface definition
The fluid's surface is defined as an iso-surface of the scalar field . It is the set of all points where the evaluated density equals a constant we call :
This definition is implied in algorithm 1 of Wu et al. and is the basis for the surface extraction algorithm described later (see the chapter Surface extraction with ray marching).
Smoothing kernels

The kernel can be interpreted as a function that "smears" or smoothes the particles' features across space to create a continuum (see figure). It must have some properties to function properly:
-
Its volume integral over the entire domain is normalized (see Monaghan). This ensures that the kernel does not amplify the feature the particle is carrying:
-
It approaches the Dirac delta distribution for small support (explained below, see Monaghan):
For simulation, kernels are typically radially symmetric, meaning
However, this property is not always desired for this application for reasons explained in a later chapter.
The choice of a kernel function is important for error considerations and practicality. The authors did not state the specific function they used - only that it was a "symmetric decaying spline with finite support". In the following, the kernel definition by Koschier et al. will be used (see figure):
Let :
where is a constant that satisfies the kernel's normalization constraint (for three dimensions ), is the particles' radius, and is a spline of the form
In this thesis, kernel functions are always understood with respect to the particle radius without stating so explicitly.
Note that this function is in fact radially symmetric, although we mentioned this to be an undesired property. It is used as the basis for a non-symmetric kernel later on. These are some of the reasons for choosing this function:
- It is simple and quick to compute.
- It has finite support, meaning . This opens the door for reducing the algorithm's time complexity, which is explained in the chapter Particle neighborhood and anisotropic kernels.
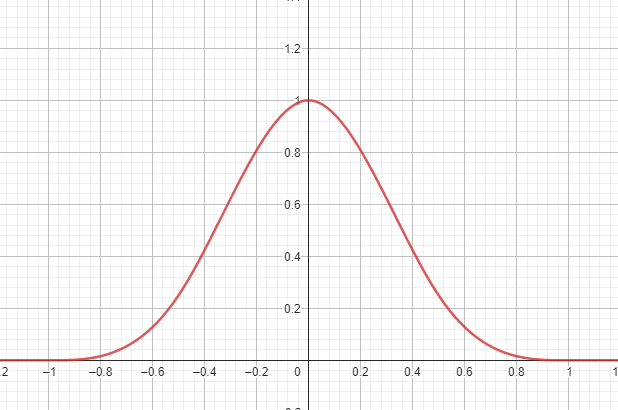
Spatial derivative of the smoothing kernel
The kernel function above is constructed in a way to be differentiable. The first spatial derivative is also continuous and smooth. It can be algebraically determined from the formula and implemented in a function directly, with no need to approximate it using numerical differentiation. will be used for calculating a normal vector of the fluid surface later on.
Implementation
What follows is the C++ code of our kernel function. It is based on the code of our fellow student Julian von Bülow. It is time-critical as it is evaluated thousands of times per frame. Hence, we made some small alterations to Julian's code to improve performance by a small margin. The full kernel code can be found in the file Kernel.cpp.
float CubicSplineKernel::W(const glm::vec3& r_)
{
float r = glm::dot(r_, r_);
if (r >= h_squared)
return 0.0f;
r = glm::sqrt(r) * h_inv;
if (r >= 0.5f)
{
const float q = 1.0f - r;
return c * (2.0f * q * q * q);
}
return c * (6.0f * (r * r * r - r * r) + 1.0f);
}
These are the optimizations applied:
- Line 6: Return from the function as soon as possible to avoid the expensive root computation.
- Line 8: Avoid divisions and instead pre-compute an inverse h_inv which can be used as a factor.
- A possible but not yet implemented improvement: Reduce the number of operations by using instead of .
Datasets
Particle representation
The internal data representation for a particle is simply a vector of three 4-byte floating-point values containing its three-dimensional position. All particles are stored in an array consecutively. We had to be wary of memory alignment in C++ as structures are typically padded with unused memory to make their size a multiple of 16 bytes. Since a particle occupies only 12 bytes of memory, we tell the compiler not to optimize the memory alignment to prevent sacrificing a third of the necessary space. This decision has to be reevaluated when attempting to port the algorithm to the GPU as the preferred memory alignment varies from device to device. It is probably wise to keep the padding bytes and align the particles in chunks of 16 bytes to make memory access for modern hardware as streamlined as possible.
Memory alignment is a complicated topic and we did not have the time to measure the performance of different alignment strategies, although it would be very interesting to see if the speed of the program would be affected by this.
Dataset generation
Thanks to the simple particle representation, datasets can be generated in a variety of ways. The generator merely has to output particle positions for selected steps of the simulation. This strongly decouples the visualization from the underlying simulation. In fact, the data does not have to be computed using an SPH approach at all.
The library we used to generate datasets is the SPlisHSPlasH framework developed by Jan Bender which exports into the BGEO file format - a compressed binary format for storing geometry data used by a program called Houdini. These files can then be imported into our program with the help of the Partio library developed at the Walt Disney Animation Studios. It handles the decompression and reading of particle data for us.
When generating datasets, a range of parameters can be set to alter the physical interactions between particles like viscosity and particle mass. Some aspects of the simulation also affect the visualization, which is why each dataset needs some parameters in addition to the particle positions:
- The number of particles may vary. Many small particles can be used instead of fewer large particles to represent an identical fluid but with more detail. Therefore, the particles' mass has to be taken into consideration when determining the iso-surface density .
- Simulation is usually translation- and scale-invariant, meaning some datasets could have a larger spatial extent than others. As a solution, one can either set the ray marching step length to a fraction of the particles' size or scale the data to attain a specified average distance to neighboring particles.
Datasets used
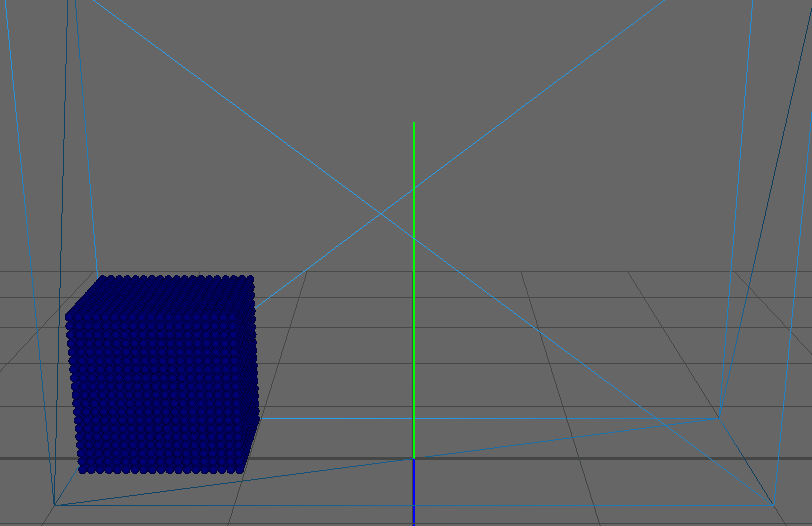

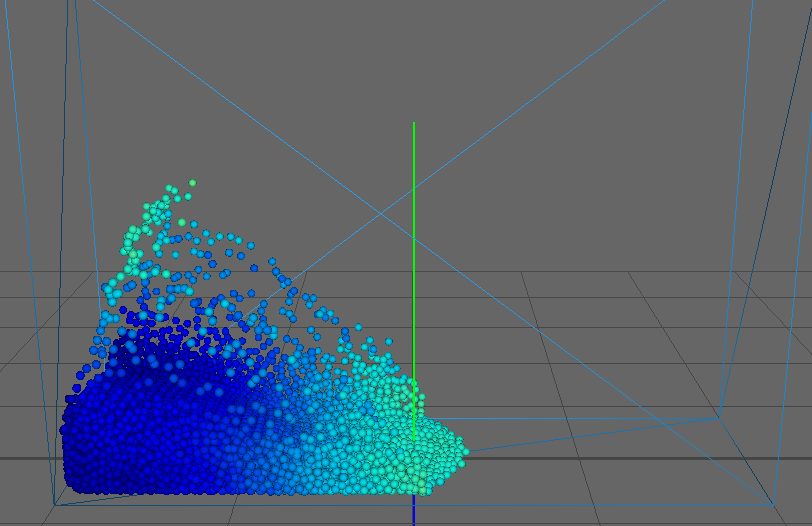
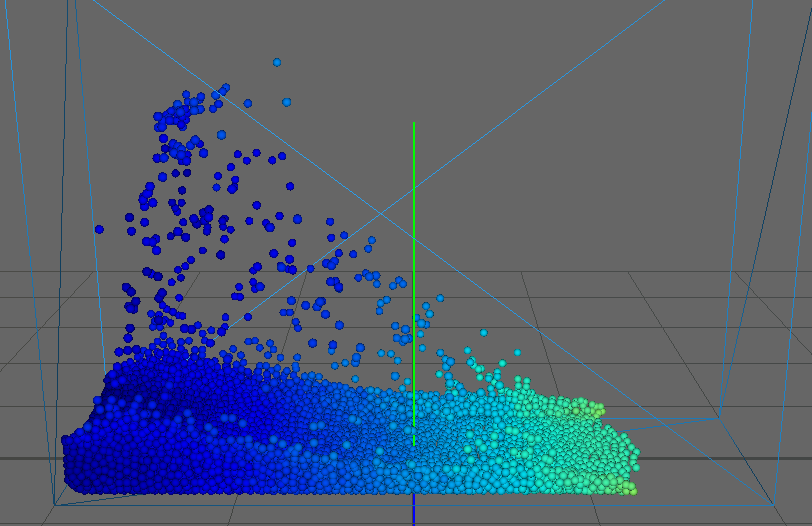
As our main dataset for tests we used a typical dam break scenario, characterized by a block of fluid that drops into a confined box (figure). This frequently used dataset qualifies perfectly for our application as it features flat surfaces at the start (the block of fluid) and intricate edges and splashes as the block collides with the box, flinging into the air on the other side. We ran the simulation for about seconds, producing frames with particles each.
Pipeline
Pipeline overview
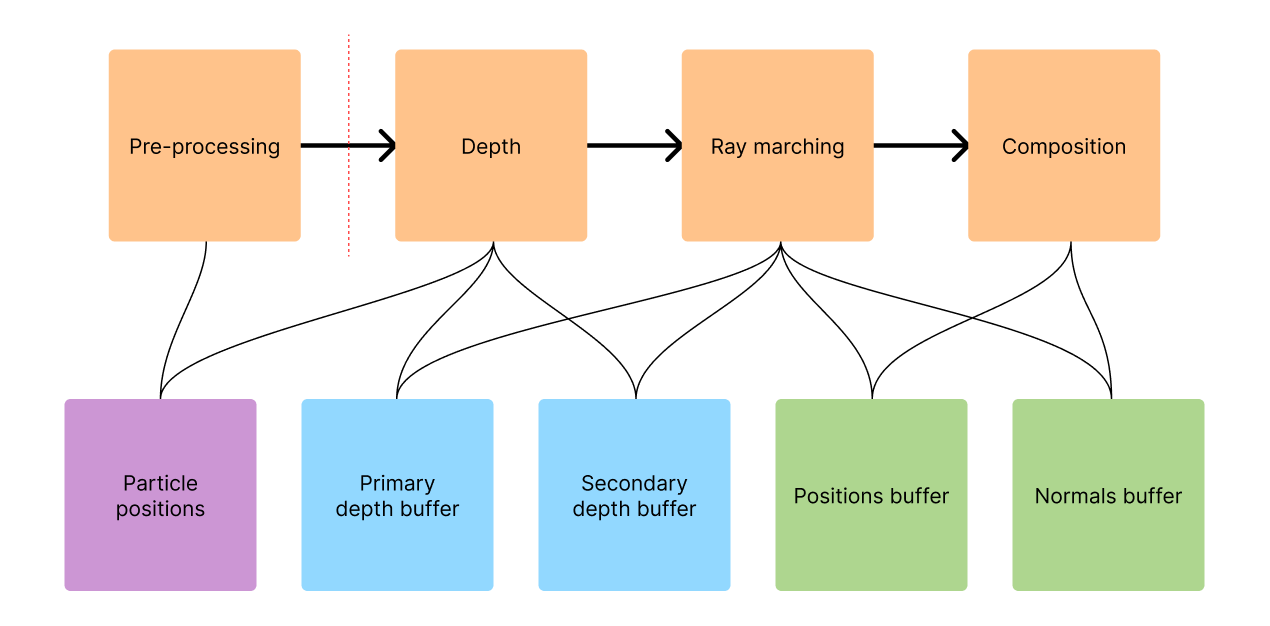
In this chapter, we show a high-level overview of the pipeline that all data flows through to eventually create an image on the screen. We aim to provide context for the following chapters that go more deeply into explaining the authors' work.
The proposed algorithm works through multiple passes, each one taking the output of the previous one as input. The input to the entire pipeline is an array of three-dimensional particle positions that represent the fluid at one particular moment in time. In this figure, we illustrate which part of the pipeline accesses which data structures.
Pre-processing
During this pass, the particle data is pre-processed and acceleration structures are built that serve the purpose of speeding up the following passes. An important note is that Wu et al. incorporate this pass into their algorithm tightly. It is executed in every frame of the visualization by processing it on the GPU. We on the other hand decided to run it only once when loading the dataset as it is the most time-consuming part of our implementation. We provide more information on how to improve on this in the chapter Future work.
Firstly, the so-called binary density grid (also called density mask in the paper) is generated (Wu et al., section 4.1). Space is divided into a grid of cells. Each cell holds a boolean value indicating whether it is at all possible for the algorithm to find the fluid's surface inside the cell. For that, the maximum density of the fluid is approximated. If it does not exceed a certain threshold, the cell can safely be skipped to save valuable computation time.
Secondly, each particle is classified as either belonging to a dense ("aggregated") or to a sparse part of the fluid (splashes). This information is used in the depth pass when deciding which depth buffer the particle should be rendered to (more in the chapter Handling splash particles).
Depth pass overview
In the depth pass, particles are rendered to a depth buffer as spheres with the radius . The positions on those spheres serve as good approximations of the true fluid surface. They are used as starting points for refinement during the ray marching pass.
Two depth buffers are filled during this pass. The authors call these and , we call them the primary and secondary depth buffer respectively. All particles are rendered to the primary buffer, but only the ones classified as "aggregated" are rendered to the secondary buffer. More information on this is provided in the sections Depth pass and Handling splash particles.
Ray marching pass overview
Rays are shot from the camera into the scene along which the fluid surface is searched. The depth buffer from the previous pass is used to compute entry points for the rays (more in the chapter Surface extraction with ray marching). Since this pass is very costly on its own, the authors provide several adaptive techniques for reducing the time spent ray marching - for example a hash grid and variable resolution.
Composition pass overview
The last step of the pipeline is to take the data computed in all previous passes and determine a color for each pixel of the screen. Here, the fluid's properties like color, refraction, transparency, and light interaction are modelled and it is embedded into the scene (more in the chapter Image composition).
Depth pass


After pre-processing has taken place, the particles are rendered into depth buffers that serve as entry points for the surface reconstruction (see figure for a visualization of a depth buffer).
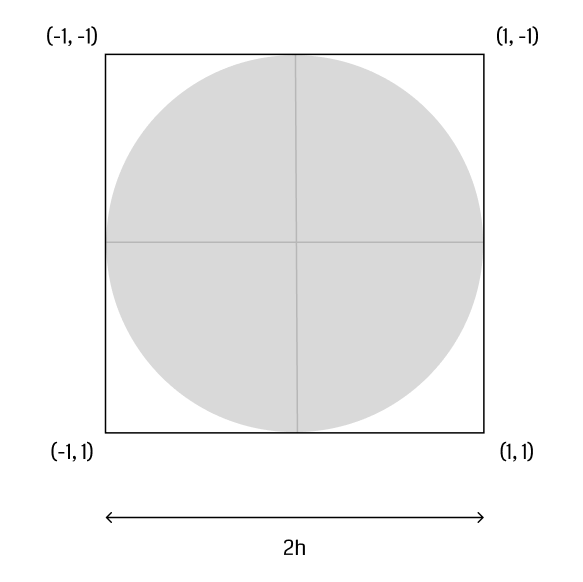
The first step is to construct a vertex buffer that holds all particles comprising the fluid. Wu et al. suggest to render a camera-facing quad for each particle with sidelength . Each vertex holds
- a three-dimensional position in world space,
- and a two-dimensional texture coordinate - for the top left, for the bottom right vertex (figure).
The vertex buffer is fed into the first render pass, which writes to the depth buffers. The value output to the buffer is:
with being the world-space distance from the particle's center and being the particle's z-coordinate. The fragment is discarded if .
This technique renders the particles as if they were perfect spheres - although they are rendered simply as two triangles - by projecting onto the surface of the camera-facing hemispheres surrounding the particles. Conveniently, by using a depth buffer for this pass, occlusion is handled efficiently by the graphics hardware.
Two depth buffers will be filled using this technique:
- the primary depth buffer (called in the paper) containing all particles
- and the secondary depth buffer (called in the paper) containing only particles belonging to a denser ("aggregated") part of the fluid volume.
The former will be used as a first estimation of the fluid's surface. The latter will be used to enable the ray marcher to skip large parts of empty space and continue at the surface again (further details in chapter Methods of acceleration).
Surface extraction with ray marching
Ray marching has gained popularity in recent years as a surface extraction method for particle-based representations as it suits the parallel nature of computation on GPUs. It can be implemented in a compute or fragment shader and executed independently. Although this is the way the authors designed their implementation, we had to refrain from following that path for lack of time. This step, however, would lead to significant reductions in computation time.
Ray marching refers to a technique of sampling some function at points along a ray and collecting information about the function in the process. In our application, we shoot rays from the camera to sample the fluid's density and find a point where the surface criterion is met (see the Surface definition). Theoretically - since the fluid is continuous -, infinitely many rays would be needed to capture the entire surface. For graphical applications, however, the finest granularity of information can be retrieved at the pixel level. Any surface information between pixels would not - at least not in the algorithm discussed here - contribute to the final image. Hence, all the following computations are performed for each pixel of the screen (of size ) labeled .
In mathematical terms, we search for a point along the ray
where the following condition is satisfied:
In the ray equation, is the starting position of the ray and is a unit-vector indicating the direction the ray is travelling in. They can be computed by applying the inverse transformation pipeline ( being the projection and being the camera matrix) to the homogenous clip space coordinates :
is looked up directly from the primary depth buffer. If , the depth pass did not output a value for this pixel, meaning there is no fluid surface to be found. In this case, the pixel can be discarded. are retrieved with the following computations. The pixel coordinates are converted to so-called normalized device coordinates:
where is the index of the current pixel counting row-wise from the origin of the screen. The origin depends on the used graphics API (OpenGL handles this differently than Vulkan, for example).
Since we are dealing with homogenous coordinates in projective space, needs to be dehomogenized to be used as a three-dimensional coordinate:
To obtain the ray's direction, we must only compute a vector pointing from the camera's position to the start of the ray and normalize it:
Now we have defined a viewing ray with an entry point right near the fluid's surface which greatly decreases the number of ray marching steps needed to find the iso-surface.
Marching along the ray
When stepping forward on the ray, it is common to increment (of the ray equation) in uniform steps at the start of each iteration. However, as the number of necessary steps is the limiting factor for performance in all ray marching algorithms, it is desirable to omit unnecessary steps wherever possible. Such optimizations are described further below. For now, we assume that in each iteration, will be moved forward by equal step sizes :
The step size should be set as a fraction of the particle radius so no particles are skipped. The first time we encounter a position where - we cannot check for exact equality when moving in discrete steps - the surface's position is assumed there. The position can then be stored in a buffer holding a three-dimensional position for every pixel of the screen. When we find the surface's position, we also want to compute the normal for lighting calculations during image composition. For this, the authors propose to sum up the gradients of the kernel function (see equation 11 of Wu et al.):
The gradient is a vector pointing radially outward from the particle's position to the evaluation point . Summing these up essentially averages over all particle's normals - weighted by the kernel function - creating a representative normal vector for the fluid surface.
Implementation
The way we implemented the ray marching is via a pool of CPU threads that is always ready to do work. When the threads are signalled, they go through each pixel of the screen and evaluate the surface parameters in the direction of the pixel. This drastically improves performance over the sequential algorithm with a theoretical speedup equal to the number of threads used because there is no need for inter-thread communication. As mentioned above, by employing the massive parallelism of graphics hardware, one can achieve much better results.
The underlying data structures are simple floating-point image buffers with sizes equal to the screen:
- the depth buffers used for determining each ray's starting point,
- a color buffer for the fluid surface's position per pixel,
- and a color buffer for the fluid surface's normal per pixel.
Image composition
In this last step of the pipeline, the computed per-pixel fluid properties are used to construct an image that will be presented on the screen. The authors did not state specifics about this phase of the algorithm, so this chapter can be viewed as an explanation of our implementation.
For each pixel, we compute
- a diffuse color,
- a specular color using Phong's lighting model (Phong),
- an environment color from reflection or refraction
and combine these to form the resulting pixel color.
The fluid's physical properties are incorporated into the computation of these colors like shininess, refraction index, opacity, and apparent color.
Normals
The authors propose a technique they call adaptively blended normals. The idea is to interpolate between two normal vectors depending on the distance of the camera to the fluid surface. One of those normals comes from the summation of the kernel's gradient - as described in the previous section. The second one is a screen-space normal that is extracted from a smoothed version of the primary depth buffer . The smoothing is a Gaussian blur that can be efficiently computed on the GPU.
This blending of normals aims to reduce the spherical features that are present in the depth buffer. Even after filtering, the particles' spherical shape cannot be hidden sufficiently when they appear big on screen - i. e. the camera is close to the fluid. Therefore, Wu et al. suggest to use to correct the screen space normal.
Implementation
We implemented this pass in a fragment shader that runs on the GPU. A triangle that spans the entire screen is rendered so that the GPU evaluates the shader for every pixel.
The following data structures are available to the composition pass:
- a world-space position of the surface for each pixel
- and a world-space normal of the surface for each pixel.
They are accessed through texture samples from the shader, using the pixel's position as texture coordinates.
Our environment consists of a floor texture that is generated right inside the shader using a combination of step and modulo functions. This way, the refractions of the fluid are made visible. Usually, an environment map of the surrounding scene would be generated that can be sampled to let the fluid reflect and refract light from the scene.
Although we did not implement the screen-space normal extraction and blending, we found the object normals to be an excellent approximation for achieving realistic lighting. However, we would like to implement this in the future to see the effect and evaluate if it significantly enhances the visualization quality.
Particle neighborhood and anisotropic kernels
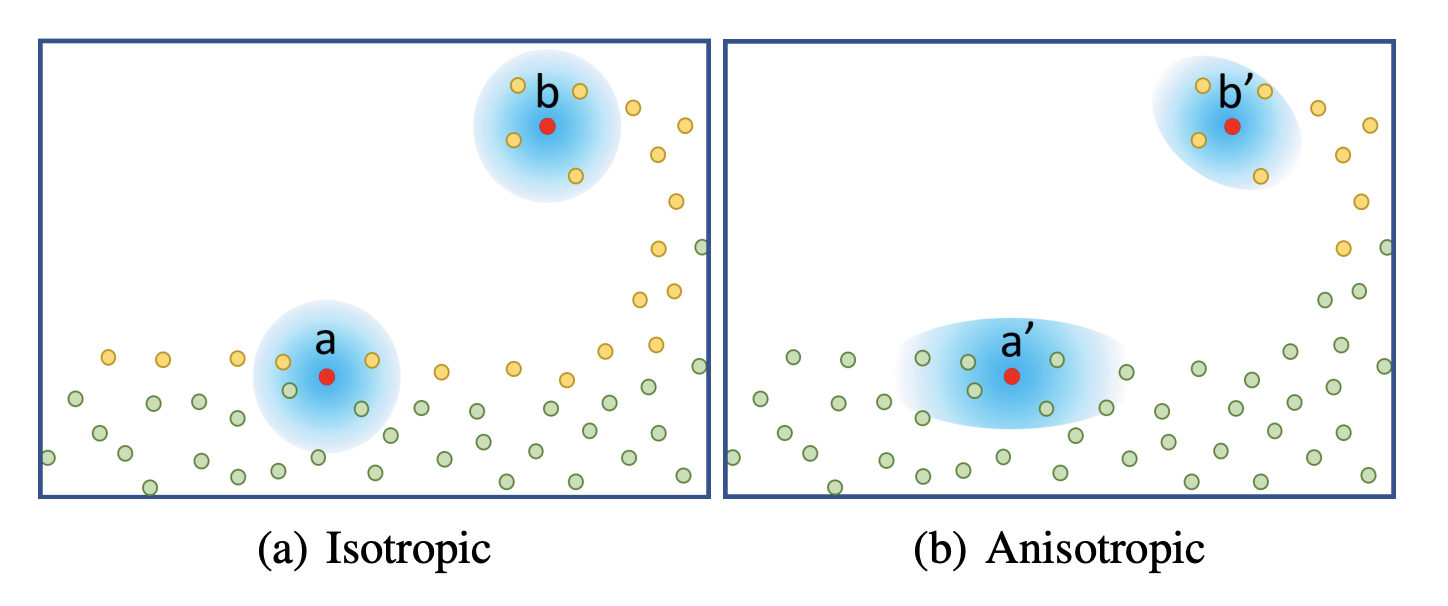
From isotropic to anisotropic
We explained the smoothing kernels used in Smoothed Particle Hydrodynamics above and called them isotropic - which can be thought of as "spherical" or radially homogenous. This property is necessary for simulation but leads to the most prominent visual artifacts of visualizing particle-based surfaces: Flat surfaces no longer look flat but rather bumpy. It can be evidently seen that the underlying representation is made up of points or spheres. The authors compared their method to multiple others, illustrating the need for a way of hiding spherical artifacts (see figure 8 of Wu et al.). To combat this, researchers have begun to develop anisotropic techniques for the extraction of surfaces from point clouds as soon as 2001 (Dinh et al.).
Interestingly, the main idea has not changed over the last 20 years seeing that Wu et al. use a very similar technique as described in that 2001 paper: For a given point in space, the configuration of the neighboring points is characterized with a principal component analysis to retrieve the main axes along which the particles are distributed. This information is used to stretch the surface in a way that better fits the particles' distribution. This has the effect of preserving sharp features like edges and corners as well as flat, homogenous areas.
In our case, "stretching the surface" means transforming the input vector to the kernel function with a linear transformation matrix consisting of rotation and non-uniform scaling (further information below in Particle classification):
Comparing to the isotropic kernel function , the authors substitute for the determinant of and apply the linear transformation to the input of . This kernel can be reduced to the isotropic kernel by setting where is the three-dimensional identity matrix.
Neighborhood definition
The neighborhood of a point is defined as the set of the indices of all particles that lie in a sphere with radius around that point:
Neighborhood search
The authors did not mention the algorithm they used to find neighboring particles. The de facto standard spatial acceleration structure for SPH-related algorithms is the hash grid. For this reason, we opted to incorporate this approach as well, leaning on the explanation by Koschier et al.. A hash grid divides space into equally sized cells. A cell index can then be computed for an arbitrary point by dividing by the cell size and rounding each entry down to the closest integer:
The cell index can then be hashed using any function to retrieve an index into a table storing some data associated with the cell. In this case, we store a list of indices of particles lying in the cell.
We use a library called CompactNSearch developed by Dan Koschier which is also used by the SPlisHSPlasH framework we use for dataset generation. It uses the technique described above to accelerate neighborhood search in a point cloud for a given neighborhood radius which is equal to the cell size . The hashing function is efficient, consisting only of simple prime number multiplications (using prime numbers ) and XOR operations ():
Koschier keeps their implementation straightforward by using the C++ standard library's std::unordered_map as a hash table, providing the custom hash function mentioned above.
Each value of the hash table holds an array of integers representing the indices of the particles contained in the cell.
So, when querying the neighbors of a point , every particle in the neighborhood of that cell has to be tested for inclusion. This is because the cells' width is equal to the search radius. The test looks as follows:
or more efficiently as calculating a root is slower than multiplication:
We use two separate search grids:
- one for density calculation - for which we set -
- and one for anisotropy calculation - for which we set .
The first one is used whenever we compute . Using the kernel's property of having finite support - meaning for -, the summation does not have to iterate over all particles of the system. Instead, we perform a neighborhood search to greatly reduce the number of operations necessary to calculate the density.
The second search grid is used for characterizing the neighborhood of each particle to obtain a transformation . It is used in the anisotropic kernel function when computing .
A naive loop over all particles means the evaluation of has a lower bound of . Because accessing the hash table is a constant-time operation, spatial hashing reduces the time complexity to approximately where is the expected number of neighbors.
It is also important to consider how cells are ordered in memory. Modern hardware implements extensive caching capabilities that are essential for performant software. Programmers are advised to keep memory locations that are accessed together close to each other. Since for every neighborhood search, 27 cells have to be looked up, it is beneficial to store these 27 cells as close to each other as possible. Koschier therefore sorts the grid in a z-curve arrangement, allowing for spatial coherence when arranging a three-dimensional grid in a one-dimensional array (see this figure for a two-dimensional illustration).

Weighted Principal Component Analysis
Principal component analysis is a common method of reducing the dimensionality of datasets to enable visualization in two or three dimensions (Koren et al.). This is achieved by finding orthogonal axes that best fit the data and project it onto a subset of those axes. Since we are not dealing with high-dimensional data, we are not interested in reducing its complexity. Rather, we want to find the axes that most closely match the configuration of points in a small neighborhood. To do this, one has to compute the eigenvectors of the correlation matrix derived from the point set.
In this section, we explain the algorithm Wu et al. use to compute the principal components. It depends on the work of Yu and Turk where an alteration of standard PCA is employed called Weighted Principal Component Analysis (WPCA). The key difference is that each point is assigned a weight that is used when computing the dataset's correlation matrix and mean .
We define the correlation matrix as not limited to evaluation at the particles' positions. This differs from our sources (Yu and Turk) in that we can characterize the neighborhood around any point in space. The reason for this is explained below in Implementation.
For weights, some isotropic smoothing kernel is used. We use the one described in Smoothed Particle Hydrodynamics:
Applying weights to the particles' positions can be interpreted as an analogy to the SPH method. It also reduces visual artifacts because there is no strict boundary between lying inside and outside the neighborhood of a point.
After computing , an eigendecomposition is performed on this matrix. The matrix is decomposed into a rotation and a scaling containing 's eigenvalues on its diagonal (see equation 12 in Yu and Turk):
Singular neighborhood configurations
Some neighborhood configurations might yield a correlation matrix whose determinant is close or equal to zero. This can happen when all points lie on the same plane. In this case, the eigendecomposition returns a small eigenvalue leading to exploding numbers when computing . To address this problem, Yu and Turk introduce a minimum for each eigenvalue as a fraction of the largest one. This way, the deformation can be controlled and parameterized to fit different use-cases.
Assuming , a new is constructed with the altered eigenvalues, limiting the ratio of two eigenvalues to a constant (see equation 15 in Yu and Turk):
We define as a function that computes as above and alters it, returning .
The parameters of this algorithm are explained briefly. Note that they are dataset-dependent and the provided values work well with our dataset.
- limits the maximum deformation relative to the largest eigenvalue. Large values lead to large deformations. We used .
- merely scales all eigenvalues. We used .
- is a threshold for the number of neighbors . The deformation is not applied for really small neighborhoods. In this case, particles are displayed as spheres whose radius can be adjusted with . This will prevent spray particles with few neighbors to be displayed as big ellipsoids. We set and .
In the following, the altered covariance matrix will be used to retrieve a transformation from isotropic to anisotropic space.
Particle classification
In order to reduce the number of ray marching steps near small bundles of particles, they have to be classified as either belonging to a dense fluid area ("aggregated") or to a sparse area (non-aggregated, splash particles). For this, the density is evaluated at each particle's position and compared to a constant. When using isotropic kernels for the density calculation, this will lead to misinterpretations at the surface of the fluid, even in aggregated locations (figure). Therefore, the authors suggest to characterize the particle's neighborhood as explained above and construct a transformation matrix for the particle to be used as an input to the anisotropic kernel . is a transformation into the coordinate system represented by , so it has to be the inverse of (note that is a rotation matrix, therefore ):
where is the altered correlation matrix from above evaluated at the particle's position .
Now, to compute the density at , we use the anisotropic kernel function and only take those particles into consideration which are in the neighborhood of :
This leads to a significant improvement in image quality as can be seen in this figure.


Implementation
Because the correlation matrix representing a neighborhood configuration is symmetric (see the following equation) and real and therefore self-adjoint - meaning and specifically for real matrices -, an algorithm called SelfAdjointEigenSolver of the Eigen library can be employed.
In the following equation, the brackets are used to differentiate indices from one another. We use to refer to the element in the -th row and -th column of matrix . Likewise, refers to the -th entry of the vector .
For :
of which follows that . This is also apparent because the outer product itself is symmetric.
Eigen uses a direct computation of eigenvalues and -vectors for three-by-three matrices by solving the equation for the self-adjoint matrix . There are iterative algorithms to achieve more accurate results but for the sake of performance, we chose to use the direct method.
Note that some math libraries automatically sort the computed eigenvectors by their associated eigenvalues in descending order. Others do not to reduce performance overhead when sorting is not needed. Eigen belongs to the latter category. We could not rely on the eigenvalues being sorted, which was one source of errors during development.
Note At first, we performed the PCA at every step of the ray marching process. This led to greater visual fidelity as the granularity of the neighborhood determination was not restricted to the particle positions. But pre-computing the PCA for every particle up front - as Wu et. al suggest and as elaborated above - and using the resulting neighborhood matrix during ray marching is significantly faster while still bringing the advantages of anisotropic kernels. It could however be possible to perform the characterization during ray marching by fully porting the program to the GPU. Evaluations concerning this will have to be made in the future.
When finding the neighboring particles using the hash grid for neighborhood characterization, we use a search radius of twice the particles' radius: . We found this to be a good compromise between over- and underfitting of the principal axes.
Recap
We have now introduced the transition from isotropic to anisotropic kernel functions and its necessity for high-quality surface reconstruction. We will now discuss the need for classification of particles into two groups. Furthermore, the key propositions of our primary source will be introduced and its effects will be evaluated.
Methods of acceleration
Up until this chapter, most aspects of the algorithm we discussed build on papers that Wu et al. used as a basis during their research. Next, we introduce the main propositions they developed, which all contribute to making the algorithm faster and viable for real-time application. In order to accomplish this, the execution time of the algorithm has to be below to be running at frames per second.
Handling splash particles
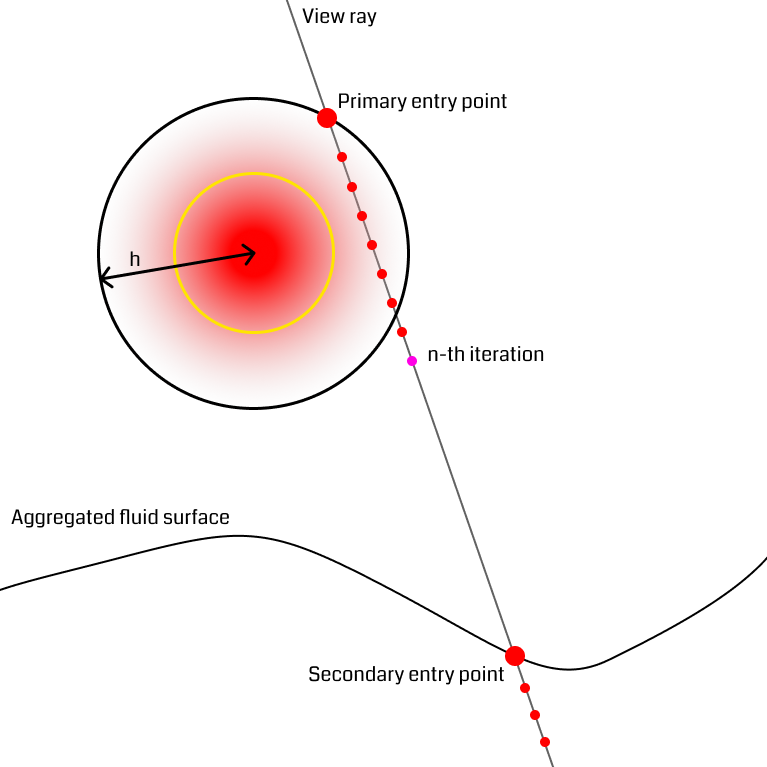
It is often the case that small bundles of particles fly up above the denser part of the fluid (figure). Consider the rays starting at the outer rim of the splash particle's sphere. When traversing through the outer part of the sphere, they are unlikely to reach the density threshold before exiting the sphere at the backside. In this situation, the ray would have to take a lot of steps to reach the next part of the fluid. The solution the authors suggest uses the previously mentioned secondary depth buffer that only particles whose density exceeds a certain threshold are rendered to, omitting low-density areas like splash particles. When a ray reaches a certain number of steps and has not found an iso-surface yet, it computes a new position from the secondary depth buffer and continues from there, effectively skipping empty space and restarting near the fluid surface. This technique once more has the effect of reducing the number of ray marching steps.
Adaptive step lengths
The authors propose a data structure that helps reduce the number of steps during ray marching they call binary density grid or density mask. This enables the ray marcher to adapt the length of steps on the ray depending on the fluid's density in the surrounding area. To achieve this, a grid of cells is generated holding a boolean value indicating whether or not a surface can be expected in this cell.
Equation 1 of the paper states this criterion for every cell :
It is now the goal to determine an approximation of the maximum possible density inside the cell.
For every point inside cell , we have (see equation 3 in Wu et al.)
where is a constant approximation of the number of particles in and around the cell . Note that has its global maximum at .
The idea for determining is similar to the neighborhood search described in the chapter Particle neighborhood and anisotropic kernels: If the cell size equals the particles' radius, only the neighborhood of each cell has to be taken into account. Wu et al. use a three-dimensional convolution on an array containing the number of particles per cell to approximate . They give a two-dimensional example illustrating their idea. Let cell be at location , then is the number of particles inside the cell located at :
with a "spatially separable" convolution kernel (see equation 5 in Wu et al.)
For three dimensions, this expands to the three-dimensional tensor with two-dimensional slices :
This convolution can once again run in parallel on the GPU, achieving computation times as low as for over particles (table 2 in Wu et al.).
are parameters that have to be carefully chosen to be not too strict and not too loose for approximating . The authors suggest to choose because the cells closer to the center are more important in the calculation and should have higher weights.
Once the grid is constructed, it is queried during ray marching before performing the expensive neighborhood search. In most cases, the query evaluates to false, meaning the position can be advanced to the intersection of the ray and the grid cell's axis-aligned bounding box. Through this technique, big parts of empty space can be skipped without the need to compute the density directly and notable performance benefits are achieved (we measured a speedup of around , but this greatly depends on the scene and viewing angle).
Furthermore, the cells can be arranged in a tree-like structure and neighboring cells with the same value can be substituted for a larger one (figure 3 of Wu et al.). Again, this reduces the number of ray marching iterations by allowing to take bigger steps.
Adaptive resolution
Another method the authors propose is to reduce the number of rays cast into the scene adaptively. The question is how to minimize the loss of information that arises when shooting fewer rays. For flat fluid areas, information between samples can be generated using linear interpolation. So, when the flatness of a region exceeds a certain threshold, rays are only shot for every two pixels and the remaining ones are filled by interpolation.
As a measure of flatness, Wu et al. suggest using the variance of the values stored in the primary depth buffer . The screen is divided into equally sized regions for which the variance is evaluated and the number of rays shot into this region is determined. Depending on two threshold values , either full resolution, half resolution or quarter resolution is used in that tile (see section 4.3 in Wu et al.):
Using adaptive resolution, the authors managed to achieve an approximate speedup of on a screen with a dam break dataset with no drawbacks in image quality (table 1 and figure 7 of Wu et al.).
Results and timing analysis

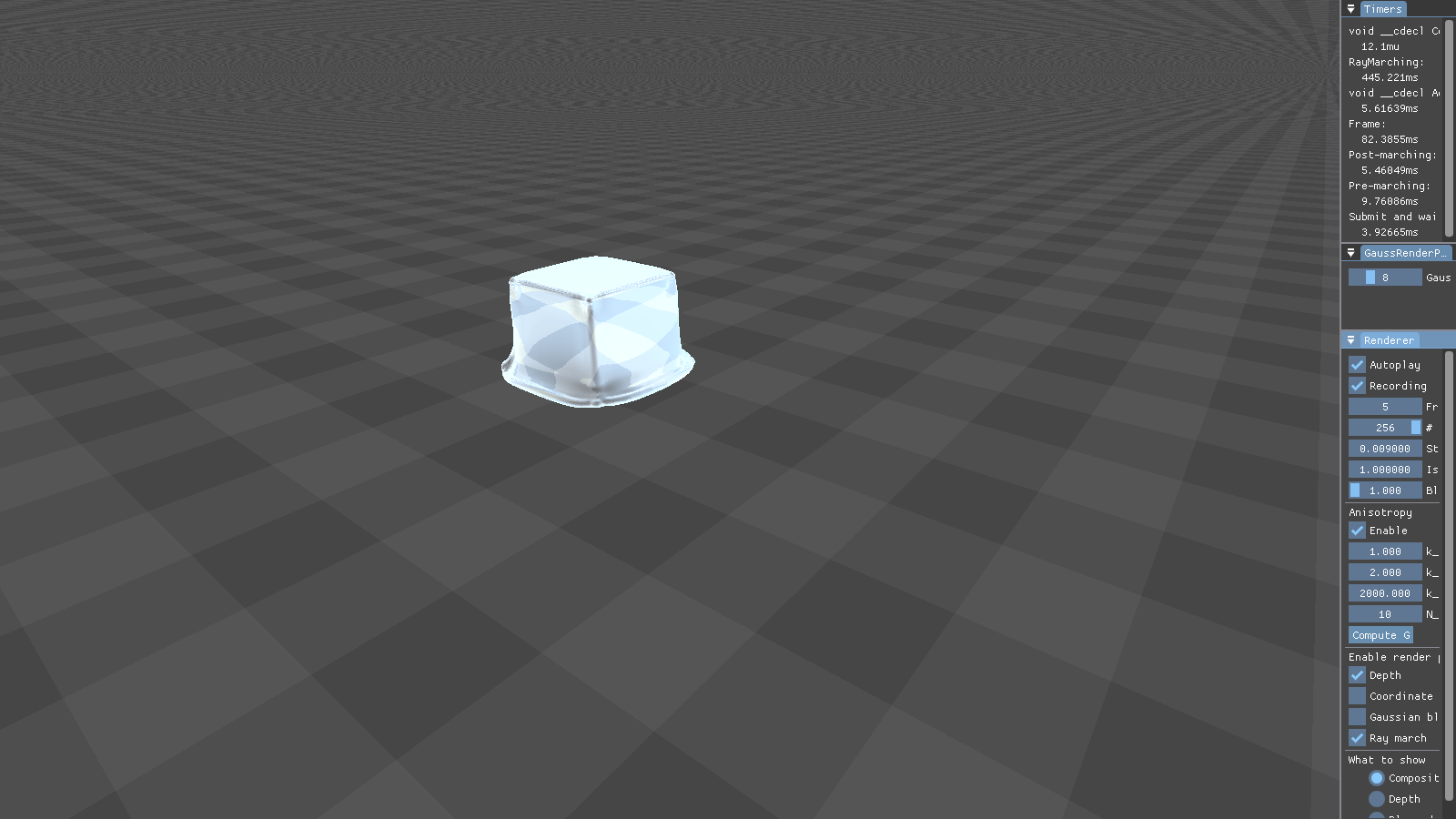


This figure shows the results our implementation can produce. Although the particles are spherical by nature, the flat faces of the initial cube configuration still appear to be flat. Particles close to each other merge into threads of fluid, creating a connected surface. Refraction, specularity, and a bluish tinge round off the illusion of water.
With many configurable parameters, the algorithm is very versatile and can be applied to all kinds of fluids. For example, Wu et al. show chocolate running down a model of a bunny in figure 10 of their paper.
Timing tests were performed on a specific frame of the dam break dataset using a screen. The exact parameters like the camera position can be extracted from the code repository. The tests ran on an AMD Ryzen 7 1700X 8-core processor and an NVIDIA GeForce GTX 1060 graphics card. On average, the ray marching took with adaptive step lengths and with equal step lengths. For this specific scenario, a speedup of around was measured. Note that there are still significant improvements to be achieved when using the techniques Wu et al. propose.
Future work
Performance
Our focus was implementing a working version of the proposed algorithms. Thus, there is a lot of room for improvement of the program's performance. The main source of performance gains will be employing the GPU. Almost every aspect of the algorithm can be implemented in some kind of shader program that the GPU can run in parallel thousands of times: computation of and ray marching iterations to name just a few. It is even possible to execute parts of the pipeline in parallel: Because no neighborhood search has to be performed in the depth pass, it can be executed in tandem with the pre-processing step. Vulkan enables a lot of customization, especially for the synchronization of parallel work, making it a natural fit for this application.
Data structure
Currently, we use multiple separate data structures for neighborhood search and the density grid. It may be beneficial to design a single structure capable of all these features. If the underlying simulation is compatible, simulation and visualization could even share the same structures so they do not have to be rebuilt multiple times per frame.
Multisampling
The images generated by our algorithm show signs of aliasing. There is a harsh edge between pixels belonging to the fluid and pixels belonging to the background. In computer graphics, a common method of mitigating this is called multi-sampling. For each pixel, multiple samples of the scene are recorded in close proximity and averaged into a single value. This can be achieved by rendering the scene to an image with higher dimensions than the screen and then downsampling it to fit. In our case, this would only have to be done to the composition image. The position and normal buffer could be linearly interpolated between pixels, keeping the ray marching phase unchanged.
Additional fluid features
Fluids can have many more features than merely color, opacity, reflection et cetera. For example, Ihmsen et al. propose a method for displaying foam and bubbles, contributing to the realism of the visualization.
Another crucial part of rendering is shadows. This is prominently achieved with a technique called shadow mapping. The scene is rendered from the perspective of a source of light. For this step, a more lightweight algorithm can be used: Instead of ray marching to find the exact surface position, a smoothed version of the primary depth buffer can be used as a good approximation.
Green suggests to render the thickness of the fluid to a texture which can be used during image composition to assign dense regions a more opaque color. This models the physical property of molecules scattering light away from the viewers eyes while it travels through a medium.
Conclusion
Wu et al. built on top of existing algorithms for screen-space surface extraction and rendering. They proposed new techniques to accelerate those algorithms and to improve the quality of the result. These consist of
- adaptive step lengths, reducing the number of iterations for each ray,
- adaptive resolution, reducing the number of rays generated,
- and adaptively blending normals, enhancing the lighting quality.
They gave little information on their implementation details. Hence, a lot of gaps had to be filled to construct a program capable of rendering fluid surfaces. To see a result on the screen, acceleration structures have to be built using hash grids and maximum density approximation. Depth buffers are filled from which the ray marcher can determine per-pixel information about the surface's position and orientation. Finally, the fluid can be brought to the screen by calculating lighting, transparency, and reflection.
There is no limit when it comes to the visualization of fluids and we are excited to see researchers develop new and improved ways to create beautiful images of them.